
¿Tienes un PDF que no quieres indexar, en una URL que sí necesitas posicionar? se pregunta el Consultor SEO Victor Reinales en una publicación de Linkedin. Para esto se plantea algunas soluciones, dentro de las que se encuentran la colocación del rel=»nofollow» en el enlace al archivo PDF, el bloqueo en el archivo robots.txt, el uso de un iframe haciéndolo <noindex> y por último, usando un archivo .htaccess.
A continuación cito la publicación para puedan leerla y comprender mejor lo que sigue en este artículo:
¿Tienes un PDF que no quieres indexar, en una URL que sí necesitas posicionar?
Existen varias formas de hace un PDF no rastreable. La primera de ellas sería un simple nofollow en su enlace:
<a href=”https://blog.example.com” rel="nofollow" >nombre del pdf</a>Simple y útil, aunque con un detalle que acotaremos más adelante. Pero ¿y si tienes 1500 PDF en la misma situación? Pues, hay que pensar un poco…
✅Una opción, no muy efectiva, sería usar el archivo robots.txt. A pesar de que la documentación al respecto no dice cómo hacerlo (todos los blogs de robots.txt tienen el mismo copy/paste), se haría de la siguiente manera:
User_agent:*
Disallow: /pagina-indexable/.pdf$Carece de efectividad debido a que esto solo haría que Google no rastree el PDF, pero no hará que Google decida indexarlo.
✅Otra opción (bastante más engorrosa, pero efectiva) es elaborar un iframe donde se inserten todos los PDF’s como source. En este caso, se puede hacer noindex al iframe mediante el meta tag robots en su html, aunque igualmente es muy poco probable que se indexe por la naturaleza del iframe.
✅Una tercera opción funcionaría trabajando un arhcivo .htaccess. Si lo creamos directamente en el directorio de nuestros PDF’s, podemos controlar que estos no sean indexables, y el resto de directorios no tendrán esta restricción. Esta opción nos la recomendó el apreciado Carlos Sánchez Donate
Si tienes un mejor método, está abierto el debate.
Texto citado de la publicación en Linkedin de Victor Reinales
Bloquear la indexación de PDF en robots.txt
Yo le propuse que la opción del robots.txt sí que era viable, la única diferencia que al código presentado por él, se debe agregar el comodín utilizado en las sentencia del archivo robots.txt
Este es el ejemplo que propuse en el comentario de la publicación:
User-agent: *
Disallow: /directoriodelospdf/*.pdf$En la misma entre el «/» y el «.pdf$» colocamos el «*», que es el comodín, que hace que comprenda cualquier cadena que lleve por nombre un archivo PDF.
Obtuve una respuesta de Victor diciéndome que «… cómo dice Carlos, eso no impedirá que se indexe el PDF. Ejemplo, si existe un enlace en una página web externa hacia ese PDF, este se va a indexar.»
Estos puntos de vista encontrados me llevan a investigar que planteo es el verdadero y a investigar más sobre el tema, pero sobre todo a hacer pruebas. ¡Esto es SEO!
En la investigación inicial toda la documentación del propio Google contradecía esta afirmación de Victor, de que el archivo robots.txt no impedirá que se indexe los PDF.
Comenzando ya con las pruebas, se cerraron PDF y se colocaron en 3 directorios:
1) En un directorio sin restricciones para la indexación:
https://claudiobenedetti.com/pdfindex/pdf-de-prueba.pdf
2) En un directorio con el bloqueo en el robots.txt:
https://claudiobenedetti.com/pdf/copia-pdf-de-prueba.pdf
3) y un tercer archivo en subdirectorio del bloqueado, para comprobar que la sentencia de no rastreo/indexación del los archivos PDF es transferido también a los subdirectorio del directorio bloqueado:
https://claudiobenedetti.com/pdf/pdf2/copia-pdf-de-prueba.pdf
Prueba en el Probador de robots.txt
En principio las pruebas hechas en el propio Probador de robots.txt del Google Search Console dice que el primero está disponible para la indicación y que los bloqueados no son indexables.
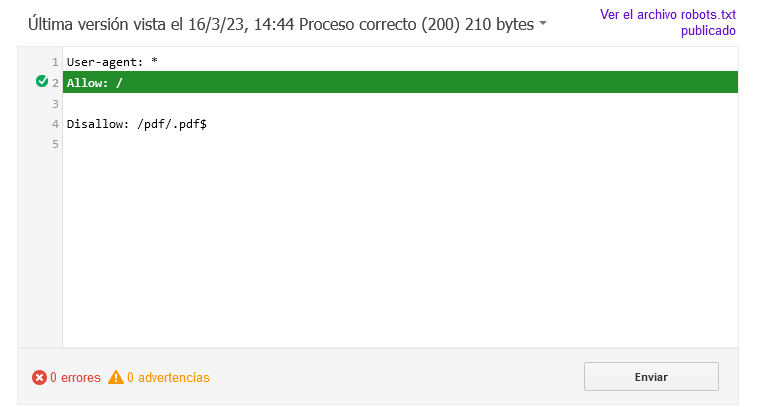

Igualmente el motivo de la prueba es comprobar que así sea y este propio artículo es parte de eso, porque va ser desde donde van a estar enlazados.
Como podrán suponer, este articulo esta destinado a ir cambiando a medida se obtengan los resultados de la prueba dentro de unos días.